
 Do any of you remember travel agents? In a long ago world (AKA the 1990s and earlier), you needed to contact and in most cases, visit a human being to find out the best rates for a flight, book that flight, get a seat assignment for a flight, and then get your printed tickets delivered to you if for whatever reason the agent couldn’t get them on the spot.
Do any of you remember travel agents? In a long ago world (AKA the 1990s and earlier), you needed to contact and in most cases, visit a human being to find out the best rates for a flight, book that flight, get a seat assignment for a flight, and then get your printed tickets delivered to you if for whatever reason the agent couldn’t get them on the spot.
Thanks to technology, I can do the same thing for a fraction of the time, cost, and effort. I can compare and purchase flights via Kayak , Hotwire or another travel site, anytime day or night and any day of the week and my ticket is forwarded to my iPhone. I can either have the email scanned or use the airline’s app for check-in and boarding. I don’t need to use an intermediary to accomplish any of these things, and I can always count on the experience to be simple and reliable.
Too bad IT monitoring rarely offers this level of dependability. In a recently concluded commissioned study by Forrester Consulting the “State of IT Monitoring,” isn’t reassuring. A majority of the 157 IT professionals interviewed expressed frustration that their monitoring tools can’t be counted on to do what they’re supposed to do.
In the companion webinar to the study, Forrester consultant John Rakowski tackled this conundrum head-on. John’s presentation was a sprawling affair that reminded me of those double albums from the 70s. It wasn’t quite at the level of Exile On Main Street or Physical Graffiti, but it was up there, as far as webinars go. John looked at everything from a working understanding of that commonly used but rarely defined term “complexity” to the influence DevOps has on the way IT organizations are set up.
I suggest you watch this webinar to get a deeper understanding of these issues because short of writing a 10,000-word essay, there is no way I can recreate it for you. Instead let me give you a taste of some of the issues behind this distrust, along with ideas of how to change this dynamic.
Battered by Event Storms
Of those 157 professionals surveyed, 62% said that “awareness of problems before end users experience them” was a primary benefit monitoring tools brought to their organization. But in a separate question, 28% of those surveyed admitted that they received performance/availability alerts via end user phone calls. This suggests at least a few of these respondents may have lacked trust in their monitoring tools to act on this awareness. Perhaps they get so many false positives that they ignored them. Or perhaps the noise caused by event storms caused them to tune out legitimate warnings.
John then asked respondents how often they are faced with the sorts of outages, performance degradation, and other availability-related issues that impact their business applications or services.
Out of this group surveyed professionals, nearly one-third said they experience these problems daily some even hourly.
Said John:
· For every single major performance or availability alert, we’re getting an influx of monitoring alerts coming into our consoles.
Signal-to-noise ratios have gotten completely out of whack. Zenoss marketing strategist Deepak Kanwar touched on the problem in his recent preview post for this webinar:
Said Deepak:
· While alerts are being generated, they simply don’t provide the insight necessary to expedite resolution. Organizations continue to circle teams of IT professionals to manually interpret the data to determine the source of service delivery problems. The alerts are not necessarily being trusted and often, the process of problem resolution does not even commence until a phone call from the user is received. And that means the damage has already been done and the service has already been disrupted.
The use of IT staff to figure out the source of multiple incidents is akin to having a phalanx of travel agents respond to each of my searches for possible travel options on Kayak. While it would give these out-of-work travel agents something to do, it’s an inefficient way to handle such queries. Given that the average IT person has more work than he can handle, this inability to offload these processes onto some reliable technology seems even more ludicrous when you think about it.
Customer-Centric Monitoring
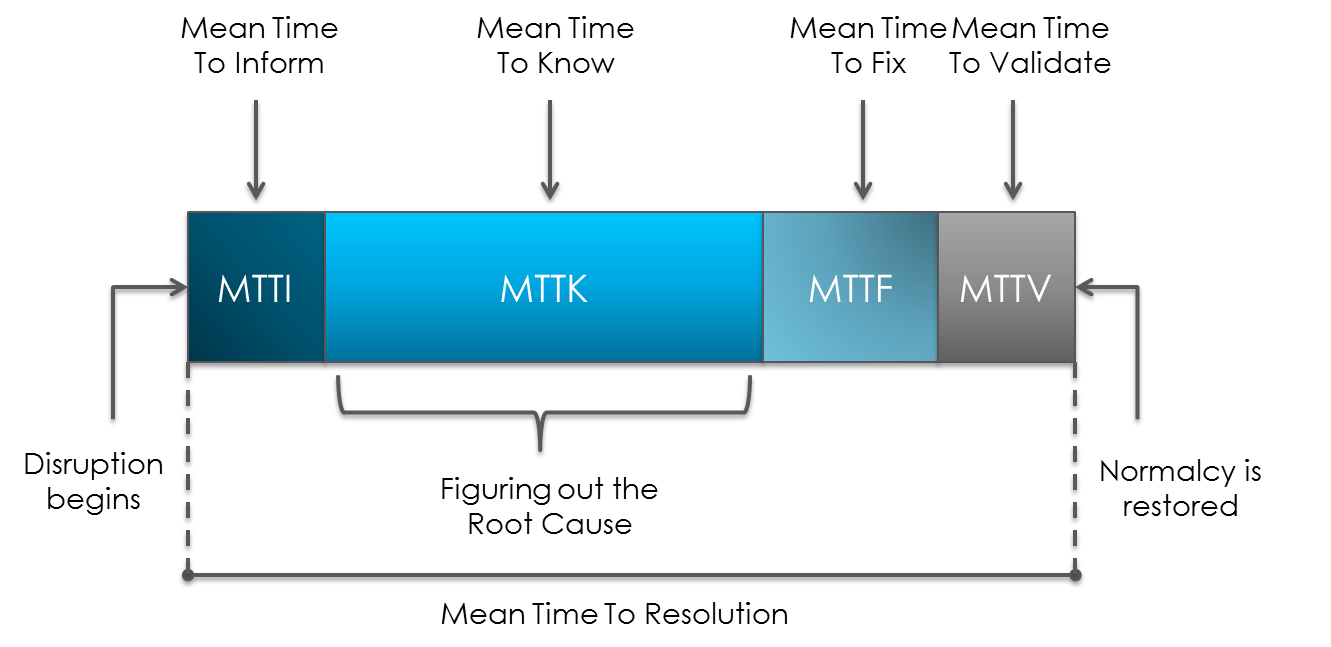
John discussed the need for what he called “Proactive Monitoring,” as the foundation for maintaining environments, preventing outages, and reducing the MTTR (Mean Time To Repair), particularly the MTTK (Mean Time To Know) portion, which is defined as the time spent on identifying the root cause for a disruption and often drags on for hours and sometimes days.
Having spent years researching these issues (this survey only reinforced his analysis), John said that a trustworthy monitoring solution must look at services from a customer-centric vantage, rather than a traditional IT-centric one. That requires a unified tool that can incorporate all the events coming in from every silo within an IT organization and triage them based on the degree they’re impacting their end users.
John cited several public IT failures to prove the importance of focusing on the end user rather than IT processes, including at least one airline snafu. And these issues continue to be commonplace even with companies that would seem to have the cash and resources to prevent them.
Recently iPhone users, including me, experienced frustration when they couldn’t download or install iOS 7 the day it was released. I commiserated with the many bloggers and commenters on various social media sites, who were frustrated by long downloading times and error messages, which in my case popped up just as the iOS 7 had almost completed its download. I’m guessing Apple’s performance issues were purposeful – after all, why spend a gazillion dollars on enough capacity for a 100 million people when your customer base is so loyal? But infrastructure issues, whatever their cause, was of no consequence from the user’s point of view. They wanted their iOS7 right now and Apple was denying them what was rightfully theirs—and so their complaints revolved around the glitches of the service as a whole.
Automating Root Cause Analysis
John said automation is the most important technological component of a trustworthy monitoring solution because it allows IT professionals to:
· detect problems and potential issues before end users do
· determine the root cause of these glitches to prevent them from reoccurring
To John’s astonishment, only 34% of those surveyed said their monitoring tools could conduct effective Root Cause Analysis (RCA). The ability to reduce the MTTK (Mean Time To Know) from hours or days to seconds is a key feature of the Service Impact component of Zenoss Service Dynamics (AKA, Zenoss Enterprise), Zenoss’ enterprise-ready IT monitoring solution.
If you can, take the time to watch John’s presentation in full to get a complete picture of the situation and why ignoring it could leave you stranded. Then, if you’re struggling with the type of monitoring problems examined in this webinar, consider giving the Zenoss sales team a call. After all, a solution like Zenoss Enterprise won’t just prevent your business from being grounded. It’ll give it the potential to soar.






